인공지능 공부/논문 구현
[인공지능 / 논문 구현] YOLO v1 구현 (1) - 데이터 셋 구성
KimDove
2022. 10. 29. 08:40
728x90
1. 데이터 셋 다운로드 받기
- classification, object detection, segmentation task를 위한 데이터 셋
- 2007, 2012년 학습 / 검증 데이터 셋과 2007년 시험용 데이터 셋을 다운 받았다.
## 데이터 셋 저장할 폴더 생성
!mkdir -p ./dataset/pascal/train
!mkdir -p ./dataset/pascal/test
!mkdir -p ./dataset/zips
!wget -P ./dataset/zips http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
!wget -P ./dataset/zips http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
!wget -P ./dataset/zips http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
## 다운로드 받은 데이터 셋 압축풀기
!tar -vxf ./dataset/zips/VOCtrainval_11-May-2012.tar -C ./dataset/pascal/train
!tar -vxf ./dataset/zips/VOCtrainval_06-Nov-2007.tar -C ./dataset/pascal/train
!tar -vxf ./dataset/zips/VOCtest_06-Nov-2007.tar -C ./dataset/pascal/test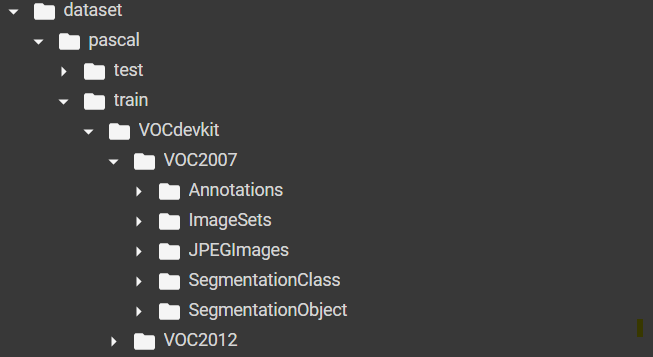
| 폴더 | 설명 |
| Annotations | JPEGImages에 있는 이미지와 매칭되는 Annotation 데이터를 포함한 폴더 |
| ImageSets | 특정 클래스가 어떤 이미지에 담겨 있는지 등의 정보를 포함한 폴더 |
| JPEGImages | Object Detection을 위한 이미지 데이터를 포함한 폴더 |
| SegmentationClass | Semantic segmentation을 학습하기 위한 레이블이 포함된 폴더 |
| SegmentationObject | Instance segmentation을 학습하기 위한 레이블이 포함된 폴더 |
1-1. 데이터 셋 확인해 보기
## 필요한 패키지 로드
from imutils.paths import list_files
from bs4 import BeautifulSoup as bs
import matplotlib.pyplot as plt
from tqdm import tqdm
import numpy as np
import cv2, os
import json
- 좌표 추출 및 데이터 시각화에 필요한 함수들 정의
- cvt_color | cv2로 이미지를 불러오면 BGR 이미지로 로드하는데, 이를 RGB 이미지로 변환해주는 함수
- get_coord | BeautifulSoup으로 파싱한 xml 파일에서 좌표정보를 추출하는 함수
- xml_parser | BeautifulSoup으로 xml 파일을 파싱하는 함수
- show_image | 이미지를 시각화 해주는 함수
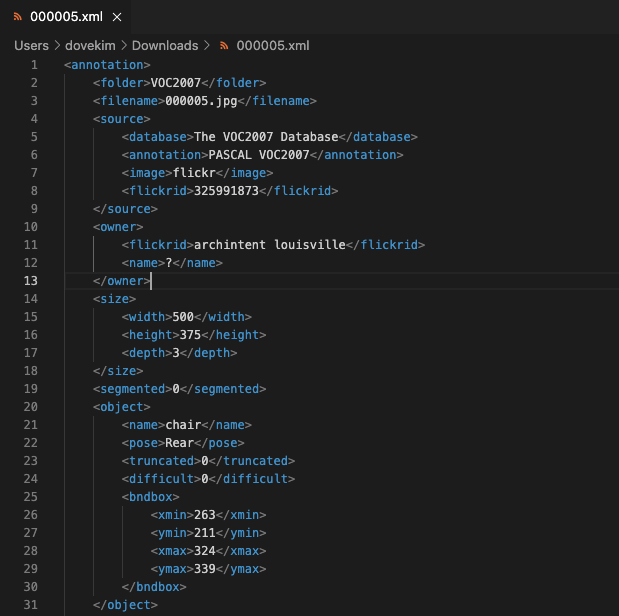
- Annotation 정보가 담겨있는 xml 파일의 태그는 아래와 같은 구조를 가진다.
| 태그 | 설명 |
| <folder> </folder> | 해당 xml과 매칭되는 이미지가 포함되어 있는 데이터 셋 폴더 이름이 담겨 있는 태그 |
| <filename> </filename> | 해당 xml과 매칭되는 이미지 이름이 담겨 있는 태그 |
| <size> </size> | 이미지의 너비와 높이가 담겨있는 태그 |
| <object> </object> | - 객체의 레이블 이름과 좌표가 포함되어있는 태그 - 객체가 여러개의 파트로 나눠지는 경우 <part></part>태그를 이용해 객체 정보가 담김. |
cvt_color = lambda image: cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
get_coord = lambda tag, coord, type=int: float(tag.select(coord)[0].text) if type == float else int(tag.select(coord)[0].text)
xml_parser = lambda xml_path: bs(open(xml_path, 'r'), 'lxml')
def show_image(image, cvt = False):
if cvt: image = cvt_color(image)
plt.imshow(image)
plt.axis(False)
return image- 데이터 셋 중에서 샘플로 하나를 뽑아 어떻게 생겼는지 확인해 보자
- imutils의 list_files 함수를 이용하여 해당 폴더에 있는 모든 파일들을 iterator 형태로 가져왔다.
DATASET_PATH = 'dataset/pascal'
TRAIN_DATASET_PATH = f'{DATASET_PATH}/train/VOCdevkit'
older_xml_paths = sorted(list_files(f'{TRAIN_DATASET_PATH}/VOC2007/Annotations'))
xml_path = older_xml_paths[0]
soup = xml_parser(xml_path)- xml파일을 파싱한 정보 중에서 filename 태그를 이용하여 이미지 이름을 가져왔고,
xml 경로를 '/'로 나눈 것을 마지막 3번째 값까지 가져와 다시 '/'로 묶어 주었다.
e.g.) dataset/pascal/train/VOCdevkit/VOC2007/Annotations/0000.xml -> dataset/pascal/train/VOCdevkit/VOC2007
file_name = soup.select('filename')[0].text
folder_name = '/'.join(xml_path.split(os.path.sep)[:-2])
image_path = f'{folder_name}/JPEGImages/{file_name}'
image = cv2.imread(image_path)
image = show_image(image, cvt = True)- xml 파일이 object > bndbox 안에 좌표가 있어 bs4를 이용해 좌표정보를 가져와 박스를 그려보았다.
bboxes = soup.select('object > bndbox')
bboxes = [
(get_coord(bbox, 'xmin'), get_coord(bbox, 'ymin'),
get_coord(bbox, 'xmax'), get_coord(bbox, 'ymax'))
for bbox in bboxes
]
for bbox in bboxes:
x_min, y_min, x_max, y_max = bbox
cv2.rectangle(image, (x_min, y_min), (x_max, y_max), (255, 0, 0), 2)
_ = show_image(image)

1-2. 데이터 셋을 전처리 해보자

- PASCAL VOC 형식의 xml 데이터 셋을 yolo format으로 변경하여 준다.
- YOLO의 bounding box 추론값은 (x 중심 값, y 중심 값, 너비, 높이, IoU)이기 때문에,
입력 좌표도 (x 중심 값, y 중심 값, 너비, 높이) 형식으로 변환된다.- 좌표값을 그대로 사용하면 연산을 거듭할 수록 연산하고자 하는 값이 커져
메모리에 무리를 주는 등의 이유로 좌표를 이미지의 너비와 높이로 나눠준다.
- 좌표값을 그대로 사용하면 연산을 거듭할 수록 연산하고자 하는 값이 커져
def normalize(bbox, w, h):
x_min, y_min, x_max, y_max = bbox
## 중심좌표와 너비, 높이는 원래 좌표 값에서
## 이미지의 너비, 높이를 나누어 정규화 해준다.
center_x = ((x_max + x_min) / 2) / w
center_y = ((y_max + y_min) / 2) / h
W = (x_max - x_min) / w
H = (y_max - y_min) / h
return (center_x, center_y, W, H)
def pascal2yolo(soup):
file_name = soup.select('filename')
width = int(soup.select('size > width')[0].text)
height = int(soup.select('size > height')[0].text)
labels = []
for obj in soup.select('object'):
bboxes = [(
get_coord(bbox, 'xmin', float),
get_coord(bbox, 'ymin', float),
get_coord(bbox, 'xmax', float),
get_coord(bbox, 'ymax', float))
for bbox in soup.select('bndbox')]
# 좌표 정규화 (xml -> yolo 형식으로)
bboxes = [normalize(bbox, width, height) for bbox in bboxes]
label = [lb.text for lb in obj.select('name')]
labels.extend(label)
return bboxes, labels, file_name[0].text- PASCAL VOC 형식을 YOLO v1 데이터 셋으로 변경한 데이터를 txt파일로 저장한다.
- txt 파일은 각 레이블에 해당하는 (인덱스 값, x 좌표, y 좌표, 너비, 높이)로 구성된다.
## pascal voc 데이터 셋에 있는 20개의 레이블들
label_set = [
'aeroplane', 'bicycle', 'bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow', 'diningtable',
'dog', 'foot', 'hand', 'head', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'
]
def save_dataset(xml_paths, dtype = 'train'):
## 전처리 결과를 폴더에 저장해주자
os.makedirs(f'dataset/preproc/{dtype}', exist_ok = True)
for xml_path in xml_paths:
soup = xml_parser(xml_path)
bboxes, labels, fname = pascal2yolo(soup)
fname, _ = os.path.splitext(fname)
txt_string = ''
text_name = f'dataset/preproc/{dtype}/{fname}.txt'
for bbox, label in zip(bboxes, labels):
bbox_str = ' '.join([str(b) for b in bbox])
label_idx = label_set.index(label)
txt_string += f'{label_idx} {bbox_str}\n'
open(text_name, 'a').write(txt_string)
1-3. 파이토치 데이터 셋으로 구성해보자
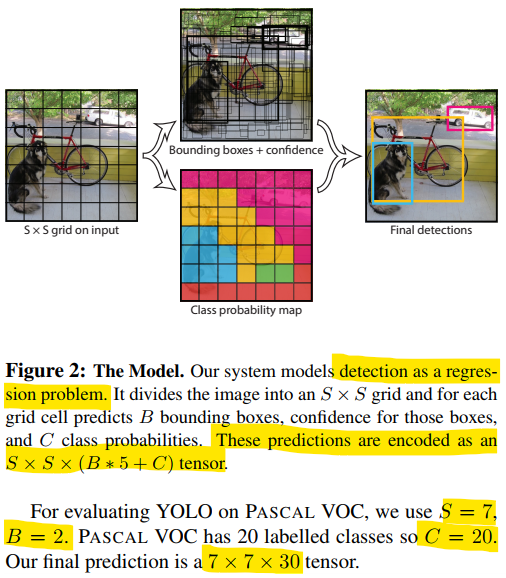
- 논문에서는 이미지를 S x S 개의 grid cell로 분할하여 추론 하도록 되어있음.
- 각 grid cell에서 B개의 bounding 박스와 각 레이블별 confidence 값들을 추론한다.
- 이미지에서의 추론 값은 S x S x (B * 5 + C) 사이즈 텐서로 출력된다.
## 필요한 패키지 로드
from imutils.paths import list_images
from torch.utils.data import Dataset
from PIL import Image
import torch
import os- 일단 텍스트 파일로 저장해 두었던 YOLO 형식의 데이터 셋이 제대로 되었는지 확인해보자
images = sorted(list_images(f'{TRAIN_DATASET_PATH}/VOC2007/JPEGImages/'))
annotations = sorted(list_files(f'./dataset/preproc'))
image = cv2.imread(images[99])
annots = open(annotations[99], 'r').readlines()
H, W, _ = image.shape
boxes = [list(map(float, annot.split())) for annot in annots]
for box in boxes:
_, x, y, w, h = box
x1, y1 = int(W * (x - w / 2)), int(H * (y - h / 2))
x2, y2 = int(x1 + w * W), int(y1 + h * H)
cv2.rectangle(image, (x1, y1), (x2, y2), (255, 0, 0), 2)
_ = show_image(image, cvt = True)
- 논문에서 나와있는 값과 동일하게 S = 7, B = 2, C = 20으로 사용하였다.
class VOCDataset(Dataset):
def __init__(self, annotations, images,
S = 7, B = 2, C = 20, transform = None):
self.annotations = sorted(list_files(annotations))
self.image_paths = sorted(list_images(images))
self.transform = transform
self.S, self.B, self.C = S, B, C
def __len__(self): return len(self.annotations)
- 각각의 grid cell에서 입력에 사용되는 인코딩된 텐서는 각각 다음과 같은 정보를 담고 있다.
- 첫 20개의 원소 | 레이블의 원 핫 인코딩 정보 ([사진 8]에서의 노란색 칸)
- 21번째 원소 | 해당 grid cell에 객체의 존재 여부 ([사진 8]에서의 회색 칸)
- 22 ~ 25번째 원소 | bounding box의 좌표값 ([사진 8]에서의 파란색 칸)
- 끝 5개의 원소 | 0으로 채워져있음. ([사진 8]에서의 하얀색 칸)
def __getitem__(self, idx):
annotation = open(self.annotations[idx], 'r').readlines()
boxes = [list(map(float, annot.split())) for annot in annotation]
boxes = torch.tensor(boxes)
image = Image.open(self.image_paths[idx])
## transform이 들어가는 경우 이미지 뿐만 아니라 box의 좌표도 변경되어야 해서 입력값에 boxes도 넣음.
if self.transform: image, boxes = self.transform(image, boxes)
## 레이블을 인코딩하여 담을 S x S x (B*5 + C) 사이즈의 텐서
label_matrix = torch.zeros((self.S, self.S, self.C + 5*self.B))
for box in boxes:
lb, x, y, w, h = box.tolist()
## i, j는 셀의 행과 열을 나타냄.
lb, i, j = int(lb), int(self.S * y), int(self.S * x)
x_cell, y_cell = j - int(j), i - int(i)
## bounding box의 grid cell의 width와 height 구하는 부분
w_cell, h_cell = ( w * self.S, h * self.S )
## object가 없다고 되어 있는 경우
## 바운딩 박스의 grid cell에 객체가 하나만 있다고 제한
if label_matrix[i, j, 20] == 0:
box_coords = torch.tensor( [x_cell, y_cell, w_cell, h_cell] )
## object가 있다고 설정해주기
label_matrix[i, j, 20] = 1
## 레이블의 인덱스 값을 1로 설정함으로써 원 핫 인코딩해줌
label_matrix[i, j, lb] = 1
## 벡터의 21 ~ 25번째 값을 박스 좌표값으로 설정해줌.
label_matrix[i, j, 21:25] = box_coords
return image, label_matrix- 이번 포스팅에서는 PASCAL VOC 데이터 셋 다운로드 및 살펴보고, YOLO 형식으로 변환 후 데이터 셋까지
구축해보았다. - 이제 다음 포스팅에서는 욜로 신경망과 평가 함수를 구현해보자.
99. 자료 출처
99-1. 도서
99-2. 논문, 학술지
- You Only Look Once: Unified, Real-Time Object Detection [논문 링크]
99-3. 웹 사이트
99-4. 데이터셋 출처
- VOC PASCAL 데이터 셋 | [데이터 셋 링크]
99-5. 들어가기에 앞서
- 논문 설명과 논문 구현을 한 게시글에 적으면 너무 길어질 것 같아 따로 적게 되었습니다.
- 같은 논문을 주제로 구현하더라도, 설명할 부분이 많아 제가 생각하는 주제별로 나눠 시리즈물로
작성하겠습니다. - 보시는데 번거로우시겠지만, 가독성을 위한 결정이니, 양해 부탁드립니다.
- 같은 논문을 주제로 구현하더라도, 설명할 부분이 많아 제가 생각하는 주제별로 나눠 시리즈물로
전체코드
GitHub - EvoDmiK/TIL: Today I Learn
Today I Learn. Contribute to EvoDmiK/TIL development by creating an account on GitHub.
github.com
내용 추가 이력
부탁 말씀
개인적으로 공부하는 과정에서 오류가 있을 수 있으니, 오류가 있는 부분은 댓글로 정정 부탁드립니다.
728x90