[인공지능 / 논문 리뷰] 1. YOLO v1 논문을 읽어봅시다.
0. 자료 출처
0-1. 도서
0-2.논문, 학술지
- Arxiv - You Only Look Once : Unified, Real-Time Object Detection | [논문 링크]
0-3. 웹사이트
- Sangne's log - YOLO v1 논문 리뷰 및 코드 구현| [블로그 링크]
0-4. 데이터셋 출처
1. 초록 (Abstract / Green 아님 ㅎ)
- 논문에서 제안한 구조의 신경망은 굉장히 빠른데,
- base 모델의 경우 1초에 45프레임을 검사할 수 있다.
- base 모델보다 작은 Fast YOLO의 경우 1초에 155프레임을 검사 할 수 있다.
- 빠른 속도로 검사가 되기 때문에 실시간 detection 검사가 가능하며,
다른 실시간 detection 모델에 비해 2배 이상의 mAP를 보여준다. - YOLO v1 논문 발표당시의 SOTA 모델과 비교하였을 당시에 YOLO가 localization에서는
더 낮은 성능을 보였으나, 배경 이미지에서의 FP(False Positive)의 비율은 더 낮았다.
⚠️ localization 성능이 낮았다 → FN의 비율이 높았다 → 객체 검출 성능이 낮았다.
배경 이미지에서의 FP 비율이 낮았다. → 오탐률이 낮았다.
- YOLO는 객체의 일반적인 모습을 학습하여, 자연 풍경 이미지로 학습 후 그림으로 검증하였을 때,
Deformable Parts Models (DPM)이나 R-CNN 같은 모델보다 성능이 향상되었다.
1. 소개 (Introduction)
- R-CNN 같은 2 stage 디텍션 모델은 Region Proposal Network(RPN) 이용하여,
이미지에서 후보 Bounding Box를 생성하고, Classifier를 이용하여 박스의 레이블을 분류한다. - 제안된 박스의 분류 후 시행되는 후처리 작업은 아래 두 가지 방법으로 bounding box를 정제한다.
1. 복제된 박스 (동일한 박스) 제거
2. 이미지에서 다른 객체를 기분으로 점수를 재계산한다. (이 부분은 잘 이해하지 못함..)
- 위 방법을 이용하였을 때, 각각의 구성요소 (RPN, Classifier)를 개별적으로
학습해야 하기 때문에 모델을 최적화 시키기에 어렵고 시간이 걸린다는 문제점이 있다.

- YOLO에서 제안한 검출 기법은 아래 과정을 거쳐 객체를 검출한다.
- 입력 이미지를 리사이즈 한다. (논문에서는 448 x 448 사이즈로 리사이즈 하였다.)
- YOLO에서의 Convolutional Network는 다수의 Bounding Box들과
Bounding Box에 해당하는 레이블의 확률을 추론한다. - NMS (Non-Max Suppression)를 통해 바운딩 박스들을 정리한다.
- YOLO 같은 1 stage 디텍션 모델에는 몇 가지 장점이 있는데,
- 초록에서 나왔던 것처럼 속도가 빠르고, 객체의 일반적인 모습을 학습할 수 있으며
다른 실시간 검출 모델에 비해 mAP가 2배 이상 향상되었다. - 기존의 sliding window, RPN같은 기법과 다르게 이미지를 전역적으로 파악하여 해당 클래스의
맥락적 정보 뿐만 아니라 모습을 encode하여 fast R-CNN에 비해 background error를 절반으로
줄일 수 있었다.
- 초록에서 나왔던 것처럼 속도가 빠르고, 객체의 일반적인 모습을 학습할 수 있으며
2-1. Unified Detection
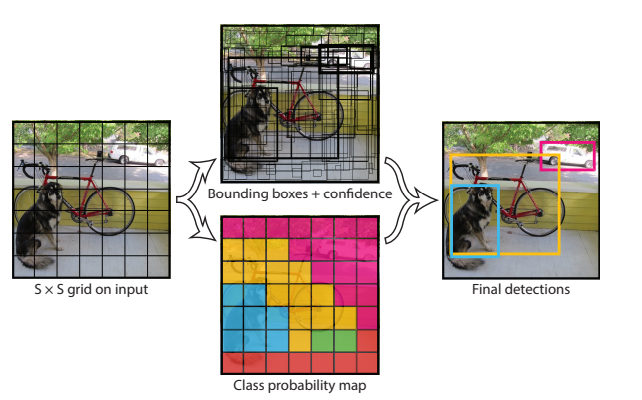
- 입력 이미지를 S x S 사이즈의 cell로 분할하여 검사한다.
- cell 안에 객체의 중심이 있는 경우에 해당 객체에 대한 검출 수행
- 각 cell 안에 B개의 bouding box들과 box 들의 confidence score를 추론하는데,
confidence score는 box 안에 객체의 여부와 box가 얼마나 정확하게 예측하고 있는지를 반영한다. - 논문에서는 confidence score를 아래 수식 처럼 정의한다.
⚠️ bounding box 안에 객체가 없는 경우 | confidence score = 0
bounding box 안에 객체가 있는 경우 | IoU (ground truth, predicted)

- 각 바운딩 박스는 (x, y, w, h, confidence) 5개의 추론 값을 가지며,
- (x, y)는 grid 경계의 상대적인 중심 좌표를 표현한다.
- (w, h)는 전체 이미지에서의 상대적인 너비와 높이를 표현한다.
- confidence는 ground truth와 predicted box 간의 IoU를 나타낸다.
- bounding box의 개수에 상관없이 하나의 cell에서 한 개의 class probability를 추론하며,
테스트 시에 아래 식으로 class-specific confidence를 계산한다.

🧹 [ 정리 ]
- 전체 이미지를 S x S 사이즈의 cell로 나누어 B개의 Bounding boxes, Confidence와
C개의 Class probabilites를 추론하며, 추론결과는 S x S x (B*5 + C)사이즈의
tensor로 인코딩 되어 반환된다.
2-2. Network Design

- 기본적인 모델구조는 feature extraction을 담당하는 convolution 층과
(좌표, 확률)을 추론하는 Fully-Connected 층으로 구성된다. - GoogLeNet의 구조에서 영감을 받아 신경망을 구성하였고,
24개의 Convolution 층과 2개의 Fully-Connected 층을 사용하였다.- GoogLeNet의 구조는 Inception module을 사용한 반면, YOLO v1에서는
Inception module을 일자로 이어둔 모델을 사용하였다. - Convolution 층에서 첫 20개는 ImageNet 데이터 셋을 이용하여
Classification task에 대한 사전 학습하여 사용하였다.
- GoogLeNet의 구조는 Inception module을 사용한 반면, YOLO v1에서는
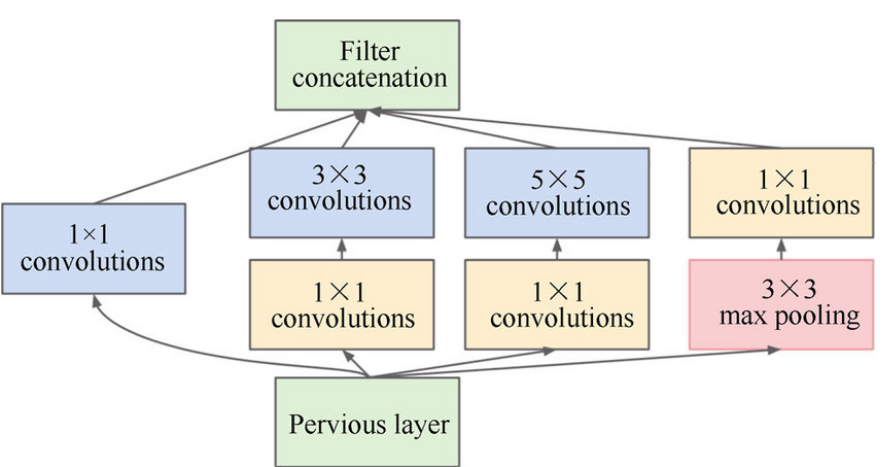

- Fast YOLO는 24개의 convolution 층을 9개의 층으로 변경하였고, Convolution 층에서의 Filter 갯수를 줄였다.
- 그 외의 모든 파라미터들은 YOLO와 동일하다.
2-3. Training
- ImageNet 데이터 셋으로 Classification task를 사전학습 시 input size를 (224, 224) 사이즈로 학습 진행하였다.
- Object Detection task에서 fine-grained visual information을 요구하여 (448, 448)로 input 사이즈를
증가시켜 학습 진행시켰다.
- Object Detection task에서 fine-grained visual information을 요구하여 (448, 448)로 input 사이즈를
- YOLO 네트워크의 출력인 (h, w)는 정규화를 통해 0 ~ 1 사이의 값으로 유계시키고, (x, y) 값은
parameterize를 통해 0 ~ 1사이의 값으로 유계시킨다. - 활성화 함수는 Leaky ReLU를 사용하였고, 로스 함수는 SSE(Sum Squared Error)를 사용하였다.
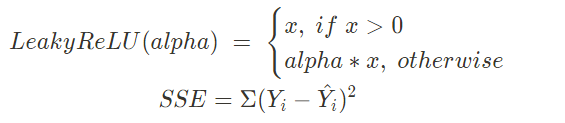
⚠️ SSE는 최적화 하기에는 쉽지만, 아래 두가지 이유 때문에 모델의 불안정성을 발생시킨다.
→ localization error와 classification error에 동등하게 가중치를 부여하는 것은 이성적이지 못하다.
→ 이미지에 객체가 존재하지 않는 cell이 많기 때문에 객체가 존재하는 cell의 confidence score가 0을 향하게 한다.
- 위와 같은 문제를 해결하기 위해 bounding box 좌표의 loss를 증가시키고,
cell에 객체가 존재하는 경우에 Confidence loss를 감소시키는 방법을 적용하였다.
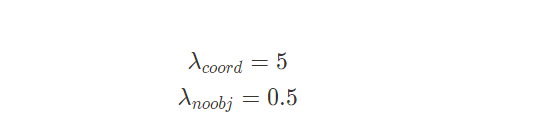
- SSE는 bounding box의 크기에 상관없이 같은 error를 사용하여 box의 width, height의 제곱근을 이용한다.
- YOLO 는 B개의 bounding box를 각각의 grid cell에서 예측하여 학습시에 각 cell에서 한 개의 bounding box만 도출되기를 원하기 때문에 bounding box들 중에서 GT와 가장 IoU가 높은 box만 선택하여 학습시킨다.
- 이 때 IoU가 가장 높은 Bounding Box를 Responsible이라 할당한다.

- 1^{obj}_{ij}는 cell i 에 j번째 bounding box가 responsible인지 나타내는 indicator function이다.
- C_i는 i번째 cell에서의 Confidence Score를 나타낸다.
- cell에 객체가 있는 경우에만 Classification Loss가 벌점이 부여되고,
bounding box가 GT에 대한 ‘responsible’일 때만 Bounding box coordinate error에 벌점이 부여된다. - 논문에서는 아래와 같은 hyper parameter들을 사용해 학습하였다.
- Epoch = 135, batch size = 64, momentum = 0.9, decay = 0.0005
- Overfitting을 방지하기 위해 dropout과 data augmentation을 사용하였다.
2-4. Inference
- 학습 시킨 모델은 PASCAL VOC 이미지에 대해 각각 98개의 bounding box를 검출하였고,
검출된 98개의 bounding box들에 대해 Non-Maximum Suppression(NMS)를 적용하였다.

2-5. Limitation of YOLO
- 각 cell에서 2개의 예측한 bounding box를 검출한 경우 GT와 IoU가 가장 높은 bounding box(responsible)에
대해서만 class를 가질수 있으므로, 근접한 작은 물체에 대해 잘 감지하지 못한다. - Train dataset에 존재하는 bounding box 안의 객체 형태와 다를때, 일반화 하는데 어려움이 있다.
- 입력 이미지가 여러 layer를 통과하여 down-sampling해서 coarse features를 통해 bounding box를 예측한다.
- 크기가 큰 bounding box에서의 작은 error보다 작은 크기 boudning box의 작은 error가
모델에 더 큰 영향을 받아 localization이 부정확한 경우가 있다.
3. Experiments

- 다른 실시간 객체 검출 모델과 성능과 속도 면을 비교했을 때 DPM모델에 비해
YOLO가 속도, mAP 면에서 월등해보인다.- 개인적인 생각으로는 DPM 계열 모델은 학습에 PASCAL VOC 2007 데이터 셋만 이용하였고,
YOLO 계열 모델은 2012 데이터 셋까지 합쳐서 사용한 것으로 보이는데 mAP 면에서
이렇게 비교하는게 맞나 싶다.
- 개인적인 생각으로는 DPM 계열 모델은 학습에 PASCAL VOC 2007 데이터 셋만 이용하였고,
- YOLO의 Feature Extractor를 VGG-16으로 학습 시킨모델과 Faster R-CNN의 Feature Extractor를
VGG-16으로 학습 시킨 모델을 비교하였을때, mAP에서는 YOLO가 6.8% 낮은것으로 보이지만,
속도는 3배정도 빠른것으로 보인다.

- 에러를 비교해 보았을때 초록에서 소개한 것처럼 YOLO가 Fast R-CNN에 비해
Localization error가 2배 이상 높은 것으로 보이고, Background error는 약 1/3 수준으로 도출되었음을 보인다.
4. 구현 해봅시다.
- YOLO 데이터 셋 구축 해봅시다.
[인공지능 / 논문 구현] YOLO v1 구현 (1) - 데이터 셋 구성
0. 자료 출처 0-1. 도서 0-2. 논문, 학술지 You Only Look Once: Unified, Real-Time Object Detection [논문 링크] 0-3. 웹 사이트 타키탸키 | Pascal VOC Dataset 탐색 및 실습 [블로그 링크] shkim5616 githu..
dove-nest.tistory.com
내용 추가 이력
- 2022.10.31 - YOLO 데이터 셋 구축 해보자
부탁 말씀
개인적으로 공부하는 과정에서 오류가 있을 수 있으니, 오류가 있는 부분은 댓글로 정정 부탁드립니다.